Fra le funzioni meglio riuscite abbiamo la modalità HDR+ e la modalità ritratto.
Quest’ultima è in grado di distinguere il soggetto dallo sfondo, che viene reso in maniera sfocata. Ciò è possibile grazie alla segmentazione semantica dell’immagine. In pratica il software è in grado di categorizzare ogni singolo pixel, distinguendo le persone dagli elementi che compongono lo sfondo.

Questa tecnologia è stata recentemente resa open source, dunque disponibile a tutti gli sviluppatori che vorranno implementarla nelle loro app dedicate alla fotografia.
Il modello reso disponibile è il DeepLab-v3+, sviluppato sulla base di una architettura a rete neurale convoluzionale per ottenere risultati il più accurati possibile.
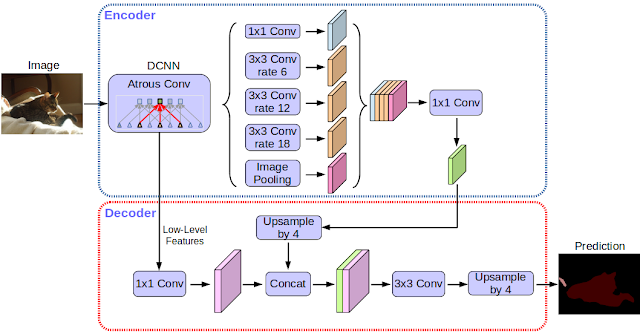
In quel di Mountain View si dicono particolarmente orgogliosi dei risultati raggiunti finora, impensabili anche 5 anni fa. La speranza è che condividendo questa tecnologia con il mondo sarà più facile sia per gli accademici che per i produttori di smartphone ottenere risultati simili e migliorare ulteriormente questa tecnologia, magari trovando per essa nuove applicazioni.